Wow, I wish we could post pictures to HN. That chip is HUGE!!!!
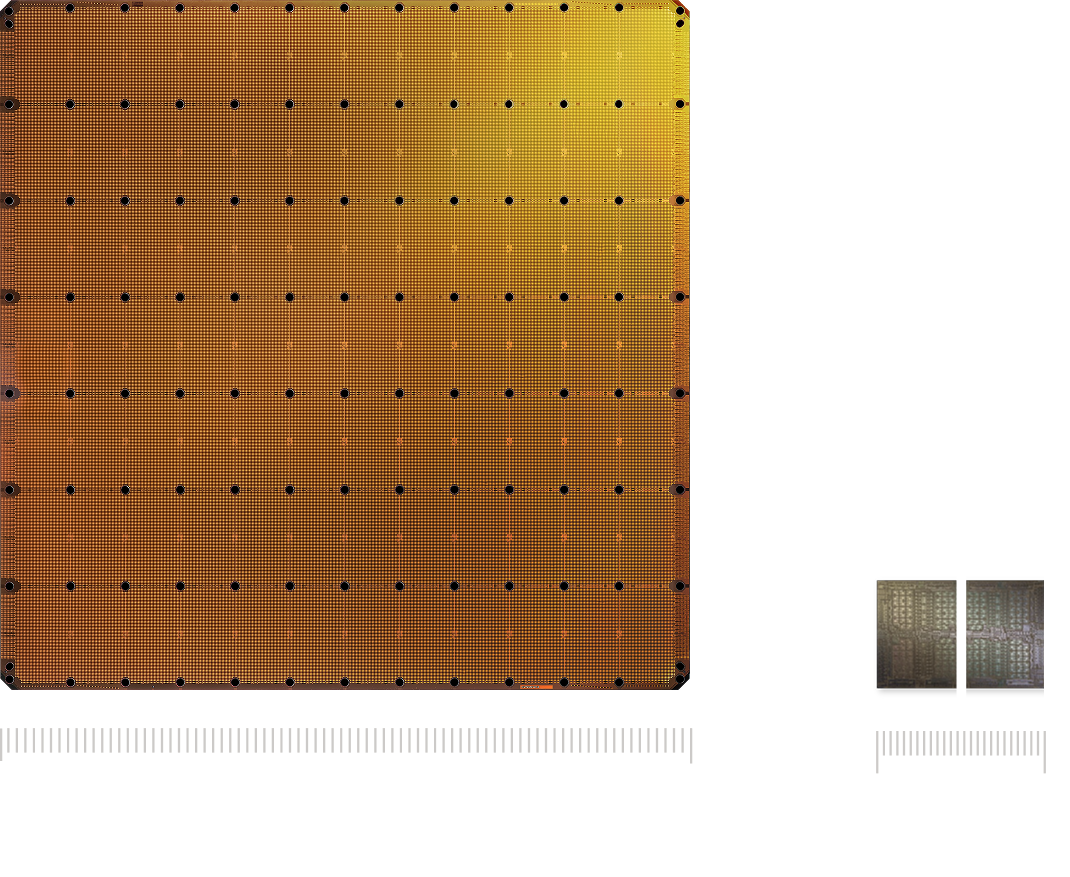
The WSE-3 is the largest AI chip ever built, measuring 46,255 mm² and containing 4 trillion transistors. It delivers 125 petaflops of AI compute through 900,000 AI-optimized cores — 19× more transistors and 28× more compute than the NVIDIA B200.
From https://www.cerebras.ai/chip:
https://cdn.sanity.io/images/e4qjo92p/production/78c94c67be9...
{kind=link}
https://cdn.sanity.io/images/e4qjo92p/production/f552d23b565...
{kind=link}
There have been discussions about this chip here in the past. Maybe not that particular one but previous versions of it. The whole server if I remember correctly eats some 20KWs of power.
Is this actually beneficial than, say having a bunch of smaller ones communicating on a bus? Apart from space constraints that is.
It's a single wafer, not a single compute core. A familiar equivalent might be putting 192 cores in a single Epyc CPU rather than trying to interconnect 192 separate 1 core CPUs externally with each other.
Yes, bandwidth within a chip is much higher than on a bus.
Maybe I'm silly, but why is this relevant to GPT-5.3-Codex-Spark?
It’s the chip they’re apparently running the model on.
> Codex-Spark runs on Cerebras’ Wafer Scale Engine 3 (opens in a new window)—a purpose-built AI accelerator for high-speed inference giving Codex a latency-first serving tier. We partnered with Cerebras to add this low-latency path to the same production serving stack as the rest of our fleet, so it works seamlessly across Codex and sets us up to support future models.
That's what it's running on. It's optimized for very high throughput using Cerebras' hardware which is uniquely capable of running LLMs at very, very high speeds.
- [deleted]
Wooshka.
I hope they've got good heat sinks... and I hope they've plugged into renewable energy feeds...
Fresh water and gas turbines, I'm afraid...
Nope! It's gas turbines
{kind=link}
{kind=link}